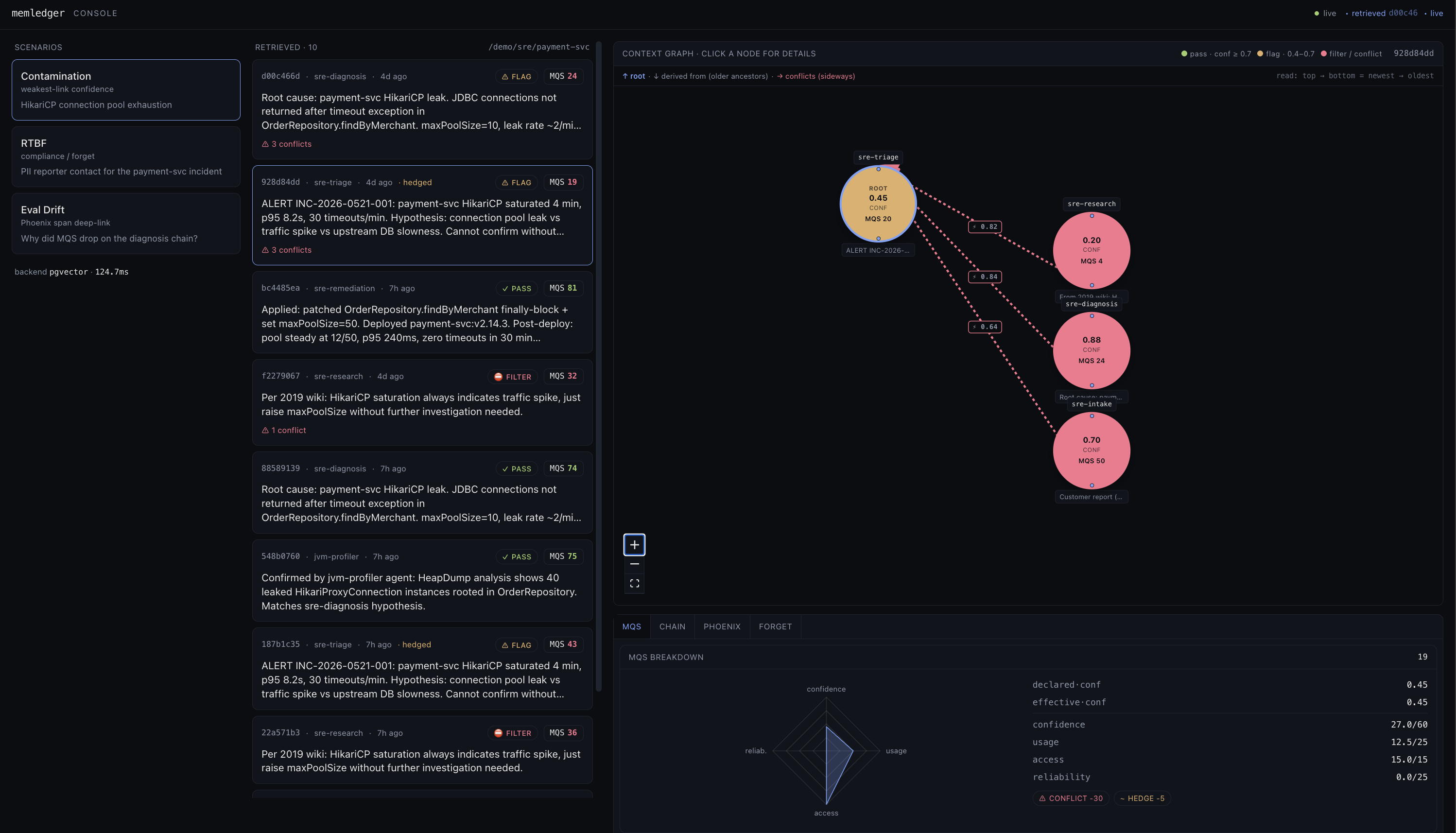
Multi-agent contamination
One agent writes a low-confidence guess. Another reads it and treats it as ground truth. The bad belief propagates silently.
memledger gates retrieval on chain-bounded effective confidence. Below threshold, the memory is filtered or flagged before your agent ever sees it.
hits = await ml.search(
query="connection pool fix",
namespace="/ops/payment-svc",
top_k=5,
confidence_policy={"min_threshold": 0.5},
)